안녕하세요!

오늘은 파이썬에서 데이터 프레임의 인덱싱에 대해서 정리해보려고 합니다.
데이터 프레임에서 원하는 특정 열과 행에 있는 데이터를 이용해서 계산하거나 확인할 때 주로 사용됩니다.
열 이름을 이용해서 하는 방법이 쉽고 간편하지만 행 이름과 위치를 이용해서 해야 할 경우도 생깁니다. (아니면 둘 다 필요합니다!)
소개할 코드는 iloc와 loc인데 저도 처음에는 이 둘의 차이점을 모르고 iloc만 열심히 썼던 것 같습니다.
이번에 정리하면서 저도 확실히 배울 수 있었어서 소개해드릴게요.
import numpy as np
import seaborn as sns
import pandas as pd먼저 필요한 라이브러리들을 불러와줬습니다.
저번과 마찬가지로 seaborn에 있는 iris 데이터를 이용해서 데이터 프레임 인덱싱 하는 방법을 소개해드리겠습니다.
iris = sns.load_dataset('iris')먼저 iris 데이터를 불러왔습니다.
iris5 = iris.head(5)
iris5.index=['zero','one','two','three','four']
print(iris5)iris 데이터를 전부 가져오면 길이가 너무 길어서 처음 5개의 데이터만 가지고 사용하겠습니다.
그리고 행이름이 숫자여서 헷갈릴 수 있으니 index에 zero부터 four까지 이름을 넣어주었습니다.
수정한 iris5 데이터를 살펴볼까요?

보면 원래는 행이름이 0:4였는데 앞에서 입력했던 zero~부터 바뀐 것을 확인할 수 있습니다.
1) iloc
먼저 사용해볼 코드는 iloc 코드입니다. iloc 코드는 행과 열의 위치를 기반으로 하는 인덱싱 코드입니다. 숫자형으로 입력해야 하며 칼럼 이름은 사용이 불가능합니다.
df.iloc[행,열]코드를 사용하는 방법은 데이터프레임.iloc[행,열]로 사용합니다.
iloc는 행, 열 자리에 숫자를 이용해서 사용합니다.
iris5.iloc[2,3]먼저 iris5 데이터에서 2번째 행과 3번째 열에 있는 데이터를 불러오겠습니다.

그 결과 0.2가 나왔습니다.
파이썬은 기본적으로 숫자가 1에서 시작하는 게 아니고 0에서부터 시작합니다.
그래서 2와 3을 입력했을 때 3번째 행의 4번째 열에 있는 데이터가 불러와집니다.
iloc 코드를 활용하는 다른 방법도 있습니다.
iris5.iloc[2]iloc 안에 숫자 한개만 넣으면 어떻게 될까요?

3번째 행의 데이터가 전부 불러와집니다. 따로 ,를 넣어주지 않으면 숫자를 넣은 행의 데이터를 전부 불러오는 것을 알 수 있습니다.
iris5.iloc[[1,4],[1,3]]내가 원하는 위치에 있는 행과 열을 불러 올 수도 있습니다.
행과 열 자리에 각각 리스트로 원하는 행 번호와 열 번호를 입력하여 그에 맞는 데이터를 불러 올 수도 있습니다.

이렇게 해당하는 행,열번호에 맞는 데이터를 불러올 수 있습니다.
iris5.iloc[2:4,2:4]이번에는 :를 이용해 슬라이싱을 해보겠습니다.

3번째~4번째 행과 3번째~4번째 열이 나옵니다. 이렇게 슬라이싱도 가능하다는 것을 알 수 있습니다.
2) loc
앞서 iloc코드가 위치 기반 인덱싱 코드였다면 loc 코드는 명칭 기반 인덱싱 코드입니다.
행 이름과 열 이름을 이용하여 데이터 프레임 속 원하는 데이터를 불러오는 코드입니다.
df.loc[행,열]사용방법 역시 iloc와 동일합니다만 행과 열 자리에 위치를 집어넣는지 명칭을 집어넣는지의 차이만 존재합니다.
iris5.loc['three','species']먼저 'three' 행의 'species'열의 데이터를 살펴볼까요?
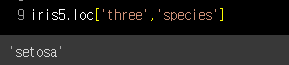
데이터 결과는 setosa가 나왔습니다.
이렇게 간단하게 살펴볼 수 있습니다.
iris5.loc['three']이번에는 'three'만 집어넣으면 어떻게 될까요?
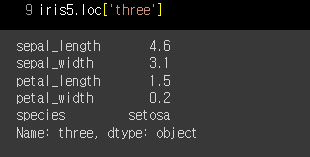
'three' 행의 모든 데이터가 출력됩니다.
행이름을 정확히 알고 있다면 원하는 데이터만 보기 편할 것 같습니다.
참고로 반대로 열 이름을 입력했을 경우는 오류가 발생합니다.
iris5.loc[['zero','three'],['sepal_width','petal_width']]내가 원하는 행과 열이 2개 이상일 경우 리스트를 이용해서 입력해야 합니다.
2개씩 입력했지만 그 이상도 가능합니다.

그 결과 zero와 three 행의 sepal_width, petal_width 열의 데이터가 나옵니다.
iris5.loc['zero':'three','sepal_width':'petal_width']iloc에서 했던 슬라이싱 역시 loc에서 가능합니다.
시작:끝 지점을 입력하면 됩니다.

그러면 zero에서 three까지 sepal_width~petal_width까지의 데이터가 나옵니다.
한 가지 차이점이 있다면 앞의 iloc에서는 2:4까지 입력했을 때 2,3번째 행과 열이 나왔다면 loc는 마지막 입력한 행과 열까지 전부 출력된다는 점입니다.
여기까지 해서 dataframe의 인덱싱에 대해서 정리했습니다.
열을 기준으로 하는 것은 데이터 프레임 바로 뒤에 열 이름 입력하면 돼서 모든 데이터를 그런 식으로 처리하려니 힘들었습니다. 근데 이렇게 행 기준으로도 하는 방법을 알게 되면서 데이터를 좀 더 다양하게 다룰 수 있게 되었습니다.
코드를 이렇게 저렇게 해보면서 연습하시면 금방 익히실 수 있을 겁니다!!
읽으신 분들에게 도움이 되기를 바라며....
오늘 하루도 즐거운 하루 보내세요( •̀ ω •́ )✧

'코딩 > Python' 카테고리의 다른 글
| 파이썬 기초 - dataframe 조건에 맞는 값 불러오기(불린 인덱싱) - (2) (0) | 2022.01.05 |
|---|---|
| 파이썬 기초 - dataframe 조건에 맞는 값 불러오기(불린 인덱싱) - (1) (0) | 2022.01.04 |
| 파이썬 기초 - dictionary를 dataframe으로 바꾸기, dataframe을 list, dictionary로 바꾸기 (0) | 2022.01.03 |
| 파이썬 기초 - 데이터 전처리를 위한 DataFrame 데이터 살펴보기 - (with seaborn) (0) | 2021.12.31 |
| 파이썬 기본 - 인터넷에서 간편하게 구동할 수 있는 구글 코랩(Colaboratory) 소개- (0) | 2021.12.30 |